
使用2captcha的服务解决登录时的极验验证码
爬虫在抓网站数据时,不可避免要和验证码做长久斗争。当然能绕过最好,但是总有绕不过的验证码,此时,对于简单的可以尝试绕过,有难度的对接打码平台。现在验证码多种多样,点选,滑动,英文字母组合等。所以要爬取一些网站的数据也越来越麻烦。
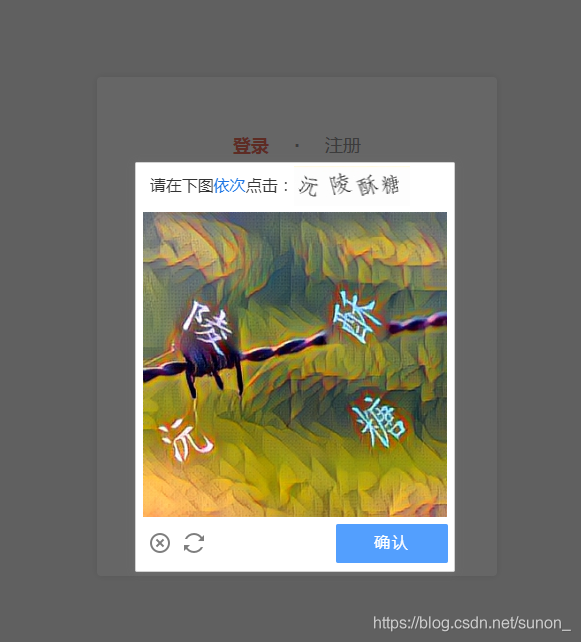
本篇就针对简书的依次点击文字的验证码进行破解
1、简书的验证技术采用的是极验提供的。
2、它的验证方式是:按顺序点击图中的文字来验证的。
3、使用第三方平台2captcha的服务
2captcha是收费的,这也是为了方便快速破掉验证码。卷积神经网络(CNN)已经学会了如何绕过最简单的验证码类型。当然也因此,验证码也早不断更新,变得更加复杂——事实上 ,这场验证码与机器学习的比赛永远不会结束。基于这个现状,目前有真实人类识别的在线反验证码服务还是要暂时领先于这些机器学习的解决方案...
本文只是利用2captcha来破解的,2captcha就是专门做这类机器学习的,它们有强大的人力物力专门做各种验证码,并且识别率非常高,现在一般都是90%以上,价格也还行,3美元几百次吧。
2captcha官网:https://2captcha.com/zh
2captcha打码平台参数分析
首先看一下2captcha的大概操作,打开官网
因为是外国网站,所以看不懂的直接利用翻译就对了。
右上角sign in登录账号
登录完成后,会自动跳到主页
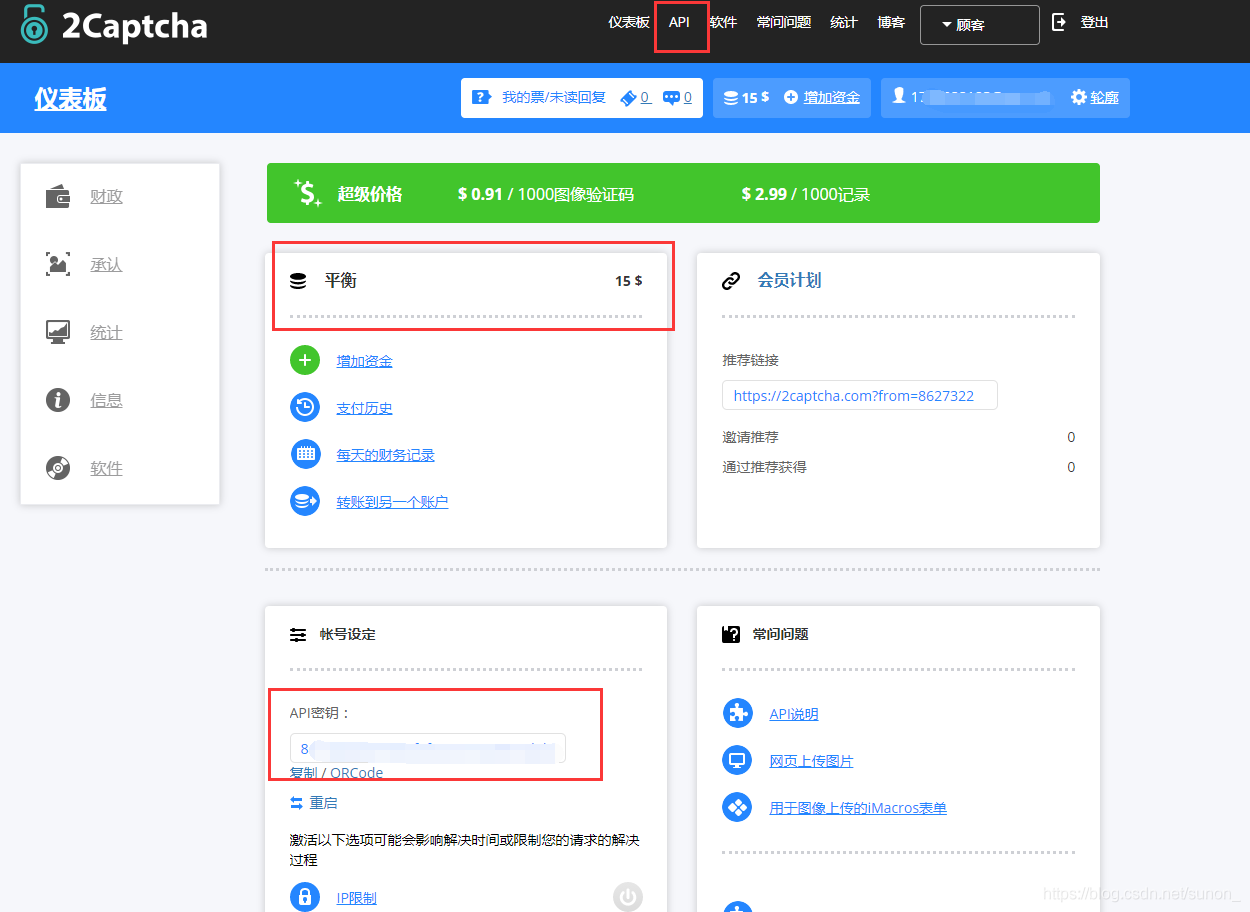
主要关注圈到的地方,15$是指余额,可以用很多次了~ 上面API就是我们主要看的地方,
下面圈起来的地方是后面请求2captcha接口需要的唯一key。
然后就是看文档了,看看具体操作,点击进入api
找到极验就行了,GeeTest
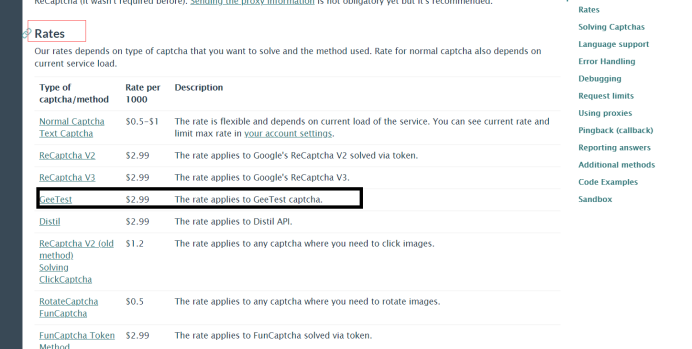
点击GeeTest
右键翻译下页面..

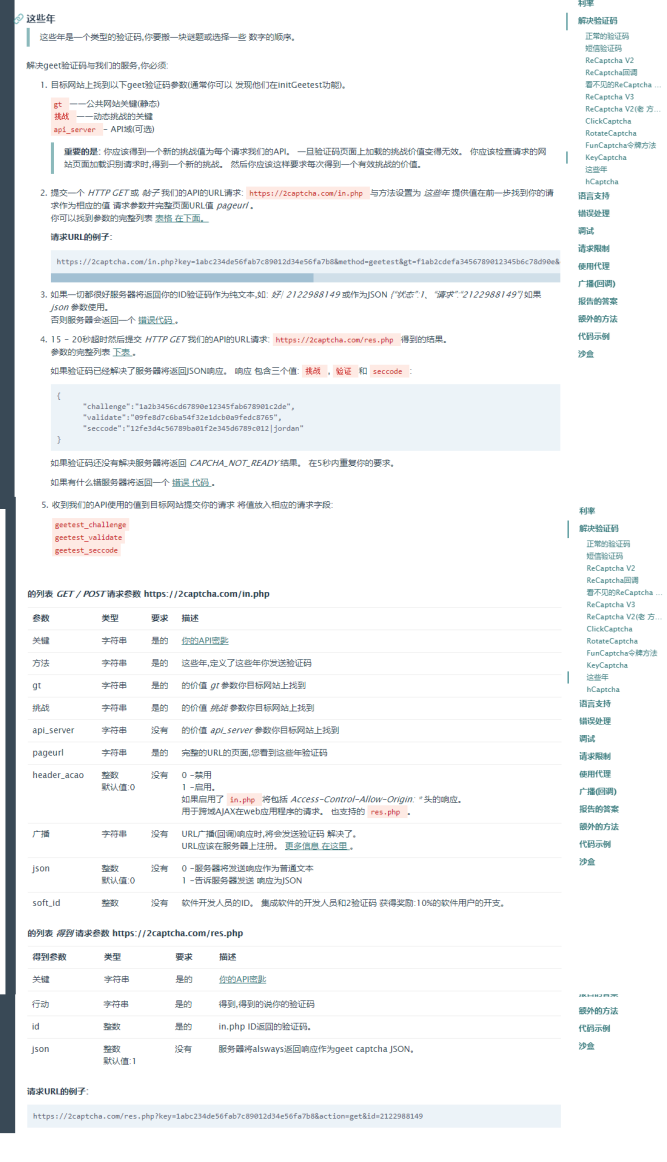
看着还是挺简单的亚子,主要就5个步骤
首先,找到目标网站的gt,challenge和api_server三个值,然后加上key、method和pageurl三个参数发送到 https://2captcha.com/in.php,会返回一个任务ID
然后等个15秒左右以后,再向 https://2captcha.com/res.php 请求,带上任务ID加上一些其他参数,会返回三个值,返回的三个值+用户名密码等的向目标网站请求,就可以通过验证了
文档已经写得很明白了,照着来就ok。
开始试一下
打开简书网站,点击登录到登录页面,f12开始寻找gt,challenge,api_server三个东西,
点击Network,刷新网页,重新加载所有请求,crtl+f,搜索challenge,发现new这个接口返回的是这个
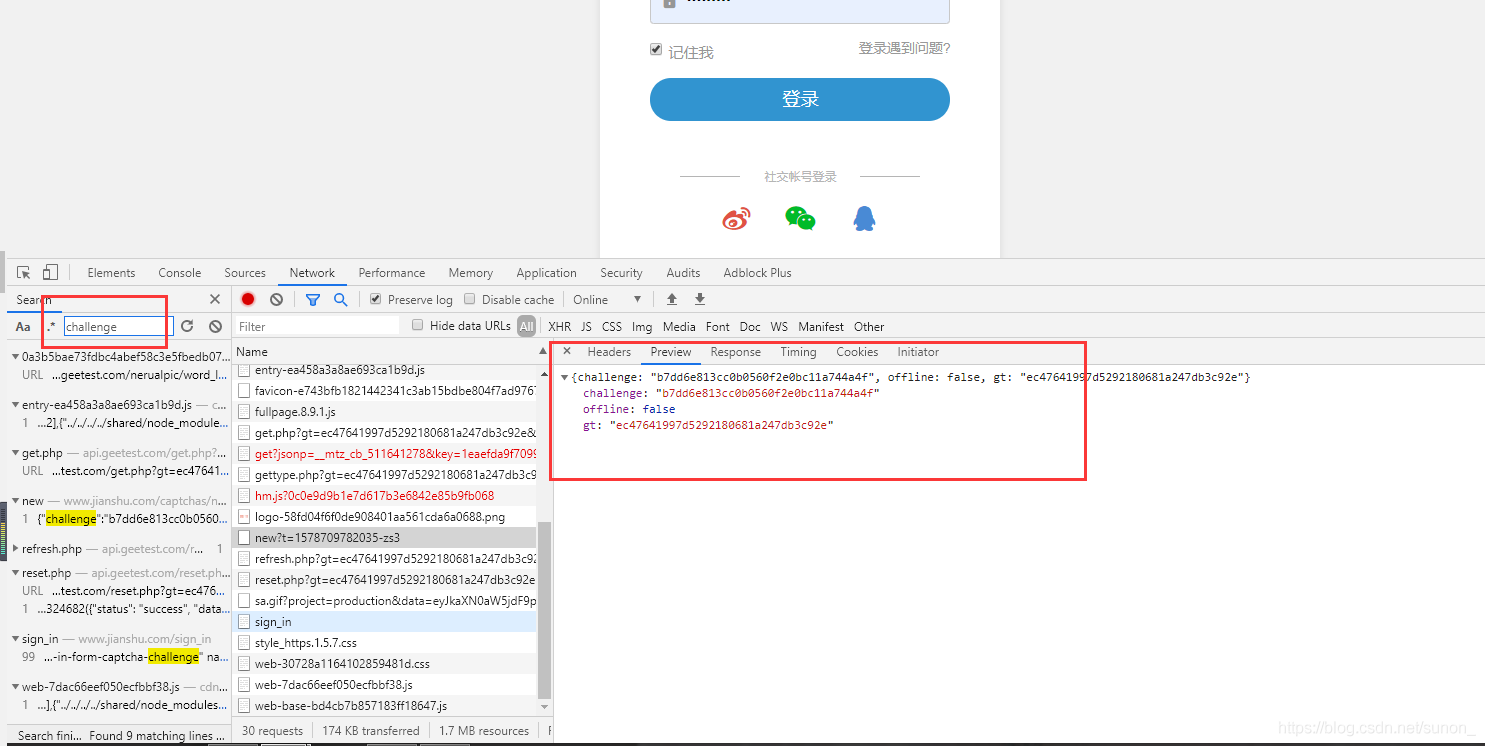
不过2captcha文档 说了,通常可以在initGeetest发现他,我们尝试下 点击Elements,按ctrl+shift+f全局搜索一下,搜索 initGeetest

还真有这个,我们打上断点,再次刷新,匹配一下是否和network里的一样
知道了gt和challenge,接下来看看api_server
随便输入账号密码点击登录一下,触发一下极验,在elements中,搜索api_server
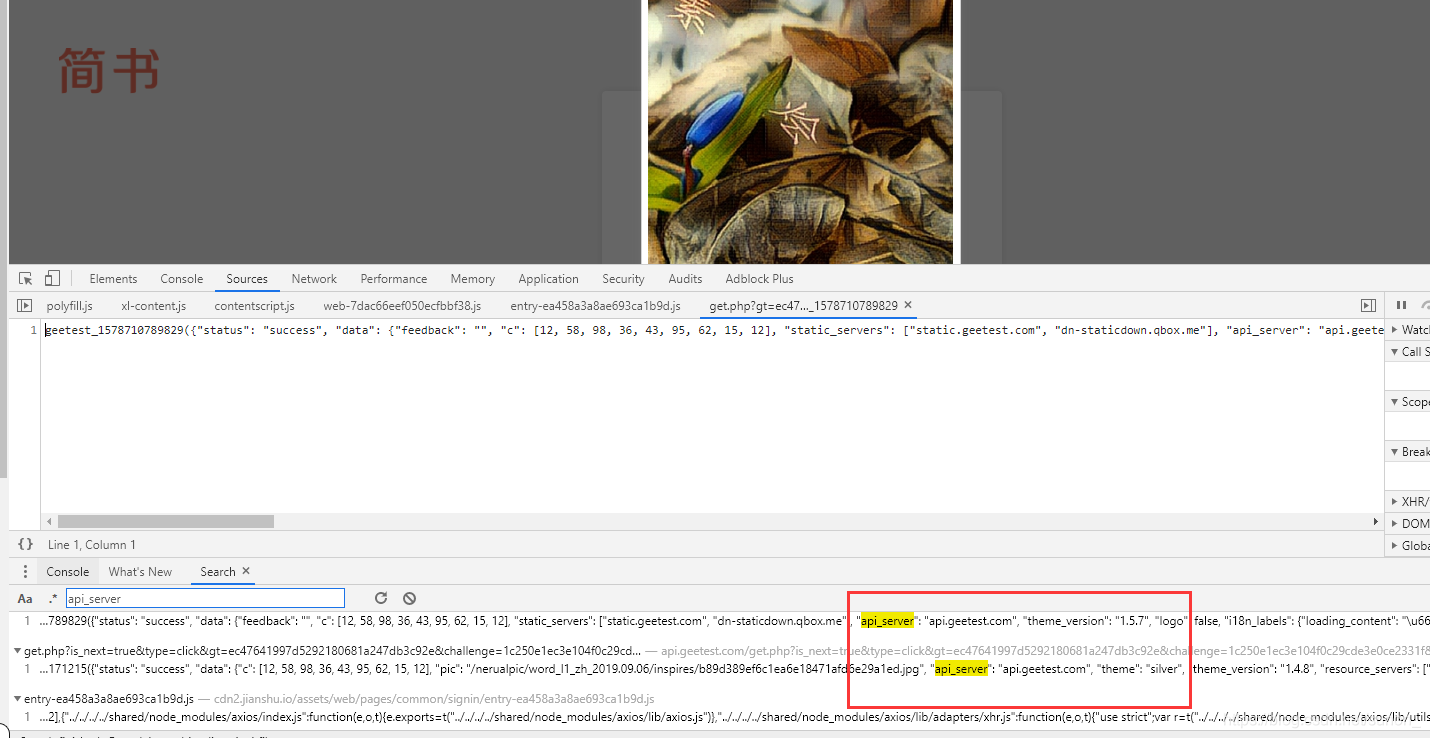
很容易就找到了api_server,api_server是固定参数,图中圈出来的就是
参数找齐了然后就是根据参数请求 https://2captcha.com/in.php
前面challenge搜索是在new接口找到的gt等,然后在Network中看Headers,发现完整请求是 https://www.jianshu.com/captchas/new?t=1578712478443-mba,我们就根据这个来获得gt,challenge
Ok,我们来请求一下
commbine_header = {
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Host": "www.jianshu.com",
"Referer": "https://www.jianshu.com/sign_in",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
}
commbine_url = "https://www.jianshu.com/captchas/new?t=1578712478443-mba "
response_commbine = requests.get(url=commbine_url, headers=commbine_header)输出结果是

成功获取gt和challenge,然后再根据2captcha文档写的利用gt、challenge和其他参数来请求https://2captcha.com/in.php和https://2captcha.com/res.php。
定义参数:
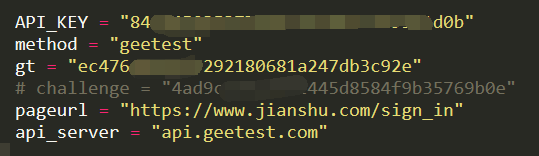
注:challenge是动态的,其他的是静态的,API_KEY是2captcha平台的key。
请求代码
def getCaptchaResult(challenge):
captcha_url = f"https://2captcha.com/in.php?key={API_KEY}&method={method}>={gt}&challenge={challenge}&pageurl={pageurl}&api_server={api_server}&json=1"
r = requests.get(captcha_url)
print(r.json())
rid = r.json().get("request")
# print(rid, type(rid))
time.sleep(15)
while True:
re_cpatcha_url = f"https://2captcha.com/res.php?key={API_KEY}&action=get&id={int(rid)}&json=1"
# print(re_cpatcha_url)
r2 = requests.get(re_cpatcha_url)
print(r2.json())
if r2.json().get("status") == 1:
geetest_challenge = r2.json().get("request").get("geetest_challenge")
geetest_validate = r2.json().get("request").get("geetest_validate")
geetest_seccode = r2.json().get("request").get("geetest_seccode")
return geetest_challenge, geetest_validate, geetest_seccode运行成功拿到了请求2captcha返回的值

参数都拿到了,只需要带着相关参数请求简书的登录接口了,在Network经过一番查找后,查到下面的这个接口。输入一个错误的密码,再输入正确的验证码就会请求下面的接口,但是密码不对登不进去。由此可断定,当验证码填写正确后应该是回调了这个方法
https://www.jianshu.com/sessions,如下图,请求这个接口需要2captcha返回的三个值外加token,用户名密码。简书的密码并没有在前台进行加密,我们只需要带这些参数访问这个接口就行了。
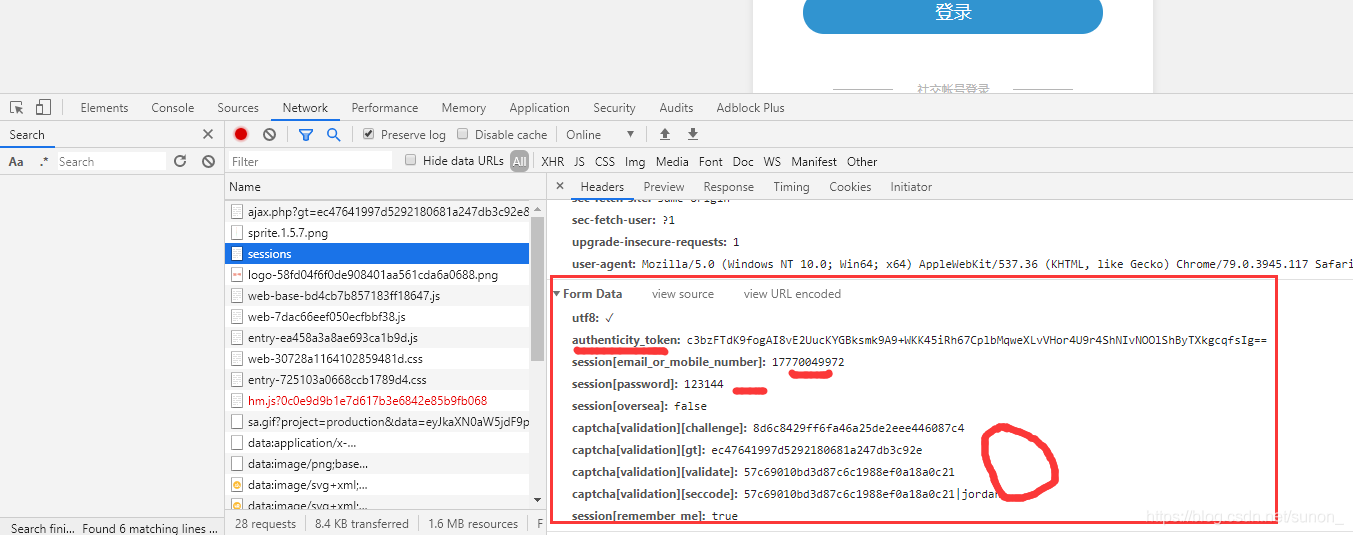
这种应该就是直接通过form表单提交的,然后我们看元素代码可以发现,确实就是这样的。

所有参数都能拿到了,接着就是带着这参数访问下,试试:
#请求方法
def login_v2():
#在浏览器中查找请求头相关参数
login_v2_header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Cookie": "__yadk_uid=vQPJojw7T; read_mode=day; default_font=font2; locale=zh-CN; web_login_version=MTU3ODcxOTQ5OA%3D%3D--5bde69ffd822460527464b558098457433cf2f17; _m7e_session_core=c83db74a121fbd0dc65f5700771914b0; signin_redirect=https%3A%2F%2Fwww.jianshu.com%2F; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216d377e679d9d-0b248d79d438a7-5373e62-2%24latest_utm_medium%22%3A%22search-input%22%7D%2C%22first_id%22%3A%22%22%7D",
"Host": "www.jianshu.com",
"Referer": "https://www.jianshu.com/sessions",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
}
login_v2_url = "https://www.jianshu.com/sessions"
r1 = requests.post(login_v2_url, headers=login_v2_header, data=login_v2_dict)
f __name__ == '__main__':
username = "177*****72" #你的用户名
password = "******" #你的密码
#根据浏览器FormData参数获取所有请求的参数
login_v2_dict = {
"authenticity_token": "c3bzFTdK9fogAI8v=k9A9+WKK45iRh67CplbMqweXLvVHor4U=ShNIvNOOlShByTXkgcqfsIg==",
"session[email_or_mobile_number]": username,
"session[password]": password,
"session[oversea]": False,
"session[remember_me]": True,
# 通过 2captcha 获取
"captcha[validation][challenge]": "",
"captcha[validation][gt]": gt,
"captcha[validation][validate]": "",
"captcha[validation][seccode]":""
}
v2_gt,challenge = getChallengeAndGt()
geetest_challenge,geetest_validate,geetest_seccode=getCaptchaResult(challenge)
login_v2_dict["captcha[validation][challenge]"] = geetest_challenge
login_v2_dict["captcha[validation][validate]"] = geetest_validate
login_v2_dict["captcha[validation][seccode]"] = geetest_seccode
print(login_v2_dict)
login_v2()执行结果

至于破掉验证码后要干嘛又能干嘛,那到底有哪些用处呢:首先当然是爬数据了,现在很多网站都是需要登录才行的;然后还有可以做自动登录啊,批量注册啊等等。。
你们可以自己试一下看。
完整代码
from pprint import pprint
import time
import random
import requests
import base64
import re
from bs4 import BeautifulSoup
API_KEY = "841545********741577a93e1d0b"
method = "geetest"
gt = "ec476419********681a247db3c92e"
# challenge = "4ad9c6d********d8584f9b35769b0e"
pageurl = "https://www.jianshu.com/sign_in"
api_server = "api.geetest.com"
def getCsrfToken():
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
id_name = "authenticity_token"
response = requests.get(pageurl, headers=headers, verify=False)
patt_id_tag = """<[^>]*name=['"]?""" + id_name + """['" ][^>]*>"""
id_tag = re.findall(patt_id_tag, response.text, re.DOTALL|re.IGNORECASE)
if id_tag:
id_tag = id_tag[0]
one=id_tag.split("value=")[1].split("\"")
return one[1]
#创建 Beautiful Soup 对象
# soup = BeautifulSoup(response.text,"html.parser")
# #print(soup.prettify())
# idVal = soup.prettify().find_all(name="authenticity_token")[0]['value']
#print(idValue)
def getChallengeAndGt():
commbine_header = {
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Host": "www.jianshu.com",
"Referer": "https://www.jianshu.com/sign_in",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
}
commbine_url = "https://www.jianshu.com/captchas/new?t=1578712478443-mba "
response_commbine = requests.get(url=commbine_url, headers=commbine_header)
print(response_commbine.text)
#print(response_commbine.json())
gt = response_commbine.json().get("gt")
challenge = response_commbine.json().get("challenge")
return gt, challenge
def getCaptchaResult(challenge):
captcha_url = f"https://2captcha.com/in.php?key={API_KEY}&method={method}>={gt}&challenge={challenge}&pageurl={pageurl}&api_server={api_server}&json=1"
r = requests.get(captcha_url)
#print(r.json())
rid = r.json().get("request")
# print(rid, type(rid))
time.sleep(15)
while True:
re_cpatcha_url = f"https://2captcha.com/res.php?key={API_KEY}&action=get&id={int(rid)}&json=1"
# print(re_cpatcha_url)
r2 = requests.get(re_cpatcha_url)
print(r2.json())
if r2.json().get("status") == 1:
geetest_challenge = r2.json().get("request").get("geetest_challenge")
geetest_validate = r2.json().get("request").get("geetest_validate")
geetest_seccode = r2.json().get("request").get("geetest_seccode")
return geetest_challenge, geetest_validate, geetest_seccode
def login_v2():
login_v2_header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Host": "www.jianshu.com",
"Referer": "https://www.jianshu.com/sessions",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
}
login_v2_url = "https://www.jianshu.com/sessions"
rust=requests.post(login_v2_url, headers=login_v2_header, data=login_v2_dict)
print(rust)
print(rust.headers)
print(rust.cookies.get_dict())
# print(rust.text)
if __name__ == '__main__':
username = "177******72"
password = "z2********9"
login_v2_dict = {
"utf8":"✓",
"authenticity_token": "",
"session[email_or_mobile_number]": username,
"session[password]": password,
"session[oversea]": False,
# 通过 2captcha 获取
"captcha[validation][challenge]": "",
"captcha[validation][gt]": gt,
"captcha[validation][validate]": "",
"captcha[validation][seccode]":"",
"session[remember_me]": True
}
v2_gt,challenge = getChallengeAndGt()
geetest_challenge,geetest_validate,geetest_seccode=getCaptchaResult(challenge)
token = getCsrfToken()
login_v2_dict["authenticity_token"] = token
login_v2_dict["captcha[validation][challenge]"] = geetest_challenge
login_v2_dict["captcha[validation][validate]"] = geetest_validate
login_v2_dict["captcha[validation][seccode]"] = geetest_seccode
print(login_v2_dict)
login_v2()
版权声明:本博客的所有原创内容皆为作品作者所有
转载请注明:来自ZJBLOG 链接:https://www.zjhuiwan.cn
留言评论